

Java Interview question-10


Question 91: How to make post method idempotent inside spring boot?
Network latency and reliability is a major issue when it comes to making RESTful application. In ideal world, when a network call is made by the client, the server receives the call and processes it before responding to the request. The client receives a response and everything is done like charm!
However, we don’t live in an ideal world where everything work as expected. The same applies to the network calls; they are not reliable. A latency in the call can make, the browser assumes the call is lost and makes another call. This is called a Retry. With retries, we face a situation where two calls are sent and we are not sure if the server receives a single or both calls.
In another similar scenario, the user might be impatient and makes another call resulting in multiple calls sent to the server (Forced retry). We cannot expect the client to not have this behavior.
So what we want to make sure of, is the server side not being affected regardless of how many requests are sent to the server. This approach is called Idempotence or Idempotency.
A RESTful API is idempotent if the state of the server is not affected by multiple unintentional calls.
Now, in the RESTFul APIs, GET, PUT, DELETE operations are idempotent by design. This means, sending a get request multiple times will result in the same outcome on the server. It does not matter if you request the data once, twice or more. You always get the expected outcome both on server and on the client. Similarly, updating a record will always have the same behavior as the updated data changes to the requested data. The multiple calls will re-change the data again to the last state which will always be the same.
However, this is not the case with POST operations. In post operations, we are requesting the server to create data, if we send more than one call, we will end up creating redundant data on the server. So here we can say, that POST operation is not idempotent by design.
Lets give an example on this to make it easier to understand. Lets suppose we have a simple customer API that receives GET, PUT, DELETE, and POST operations as following:
GET /customer/id : in this request we are requesting the server to get the customer by passing an id. First call will retrieve the customer, a retry will safely retrieve the same customer object as well without changing the state of the customer on the server. This means that GET operation by design is idempotent.
PUT /customer (customer data in body) : In this request, we want to change the customer name Jack to John. Se we send an updated customer object where the id of the customer is given in the body {“id” : 1, “name” : “John”}, now on the server, we will change the customer id 1 name to John instead of Jack. With retries, even if the first call was executed, we are still changing the customer id 1 name from John to John. The outcome is still the same, its always {“id” : 1, “name” : “John”} on the server. So we can safely say that PUT by design is idempotent.
DELETE /customer/id : In this request we want to delete the customer with id 1 from our server. So we send a call as DELETE /customer/1 to the server, and the server will delete customer 1. In the retry, we will attempt to delete customer ID 1 even though its already deleted which will do nothing; resulting in the same outcome (customer 1 is deleted). So we can say that DELETE by design is idempotent.
Keep in mind that sending a delete request may not be idempotent if we send a request like DELETE /customer/last. As this will attempt to delete the last customer entered, a retry call will delete the last customer entered again which is a different customer this time.
POST /customer (customer data in body) : Now here is the trick. We are creating a new customer {“name” : “John”} when we send this request, the server will create a new customer object with ID 1. A retry call will create the same customer but with ID 2. This will result in an unwanted redundancy. We have multiple records where we only intended to have one only.
Therefore, to build a fault-tolerant RESTful API, we need to make sure that it is idempotent. Sending retry POST operations should not create multiple unwanted records.
We will review three approaches to deal with redundancy and making our POST request truly idempotent:
Logical Waiting Time approach
POST-PUT approach
Idempotence Key approach
Logical Waiting Time Approach
When I first encountered this issue years ago, my idea was to change the POST endpoint to check if identical requests were sent multiple times within a defined period (lets say 5 seconds), and only then process the request. I call this approach: logical waiting time approach.
If the same data is sent multiple times from the same ip address, within 5 seconds, ignore the second call and do not process it. This seems to work for a lot of times as network latency is stable and less than 5 seconds most of the times.
However, this is not an ideal solution, as we are assuming that network latency does not exceed 5 seconds. In a slow network, and overloaded servers, this approach fails and fails to prevent unwanted multiple records creation.
Even in a stable network, lets assume we want to intentionally create two customers with the name “John”. This means we have to wait 5 seconds for both calls to be successfully be executed and not viewed as retries. Otherwise, the second John will be ignored by the server.
POST-PUT Approach
Another approach I used was the post-put approach. In this approach, I used to send an empty POST request to the server to create a temporary record, and return its ID. Once the ID of the temporary record is received at the client, the client will immediately send a PUT request to update the temporary record with the permanent record.
Lets run our example here with this approach. First we will send a POST request to /customer/temp endpoint. On the server, a temporary record will be created (flagged as temporary on the server). This will return an ID of the record. Now if multiple calls where sent, more than one temporary record will be created Lets say temporary customer 4 and 5 were created on the server.
Now, the client will receive a temporary ID (eg. 5) and use it to send the real data {“id” : 5, “name” : “John”} as a PUT request that removes the temporary flag on id 5. Since PUT is idempotent, we do not need to worry about multiple requests. On the server, customer 4 is flagged as temporary and should be ignored in all operations or deleted permanently later.
Now, even though this approach works perfectly, it still has one big disadvantage: maintenance. We have doubled our efforts to write such operation. Instead of one request, we are dealing with two requests, and each has its own logic on the server. We also need to flag temporary redundant calls so they are not used later on. We also need to run a cleaning operations that deletes unwanted temporary data periodically. So the maintenance is very high and expensive to implement this approach.
This leaves us with our last approach.
Idempotence Key Approach
The best approach, that I have implemented to deal with redundant POST requests, is what I call Idempotence Key approach. In this approach we add a unique key along with the post request and save this request on the server. If the server receives multiple calls with the same key, they redundant calls will be ignored.
The key is generated on the client side. To make the key truly unique we can use UUID format and put the key in the header of the post request. Lets take this to our example.
When we want to create the customer John, we attach this header to the call:
idempotency key : 79ac1a5b-192f-420c-b401-fadb8bef2c3e
When the server receives the call, it will first check the key and only creates the data if a data with the same key doesn’t exist. Now if the server received multiple requests with the same key, it will know that this is not a unique call and it is redundant, therefore it will ignore the request.
In this approach, it is important that the client generates new keys for new requests. Only retries should use the same key, otherwise we are not solving the redundancy issue.
To wrap things up, idempotence is very important to build a system that is fault-tolerant by design. Of course, not all post requests need to be idempotent, it only matters for critical operations where making double record is a real issue, like payment operations.
Question 92: What are the design principles of Microservices?
Modularity: Services should be self-contained and have a single, well-defined purpose.
Scalability: Services should be able to scale independently to handle the increasing load.
Decentralization: The system should be decentralized, allowing for loosely-coupled services.
High Availability: Services should be designed to be highly available to ensure system reliability.
Resilience: Services should be designed to handle failures gracefully.
Data Management: Services should manage their own data and not share a common database.
Statelessness: Services should be stateless to allow for easy scaling and caching.
Independent Deployment: Services should be deployable independently of other services.
Observability: The system should have built-in monitoring and logging capabilities to allow visibility into system behaviour.
Automation: Deployment, testing, and scaling should be automated as much as possible.
Question 93: What is the advantage of microservices using Spring Boot Application + Spring Cloud?
Improved Scalability: Microservices architecture allows for better scalability by allowing services to be developed, deployed and scaled independently.
Faster Time-to-Market: By breaking down a monolithic application into smaller, self-contained services, development teams can work in parallel and iterate more quickly.
Resilience: Microservices provide improved resilience by allowing services to fail independently without affecting the entire system.
Better Resource Utilization: Microservices allow for better resource utilization as services can be deployed on the best-suited infrastructure.
Increased Flexibility: Microservices architecture provides increased flexibility as new services can be added or existing services can be updated without affecting the entire system.
Improved Maintainability: Microservices provide improved maintainability by reducing the complexity of the overall system and making it easier to identify and fix problems.
Technology Heterogeneity: Microservices architecture enables technology heterogeneity, allowing for the use of different technologies for different services.
Improved Team Collaboration: Microservices architecture can improve team collaboration by breaking down a monolithic application into smaller, self-contained services that can be developed by smaller, cross-functional teams.
Question 94: Which design patterns in microservices are used while considering database?
Common design patterns used for database design in microservices are:
Database per Service: Each service has its own database, allowing for a high degree of independence and autonomy.
Shared Database: A shared database is used by multiple services to store data that is commonly used across the system.
Event Sourcing: The state of the system is stored as a series of events, allowing for better scalability and fault tolerance.
Command Query Responsibility Segregation (CQRS): Queries and commands are separated, allowing for improved scalability and performance.
Saga: A long-running transaction is broken down into smaller, autonomous transactions that can be executed by different services.
Materialized View: A pre-computed view of data is used to provide fast access to commonly used data.
API Composition: APIs are composed to provide a unified view of data from multiple services.
Read Replicas: Read replicas are used to offload read requests from the primary database, improving performance and scalability.
Question 95: Explain the Choreography concept in microservice?
Choreography in microservices refers to the way in which services communicate and coordinate with each other without the need for a central authority or central point of control. Instead, each service is responsible for handling its own behaviour and communicating with other services as needed.
In a choreographed system, services exchange messages or events to coordinate their behaviour. For example, one service might send an event to another service indicating that a certain action has taken place, and the receiving service can respond as necessary.
The main advantage of choreography is that it provides a more decentralized and flexible system, where services can evolve and change independently. This can lead to improved scalability, as services can be added or removed without affecting the entire system. Additionally, choreography can improve reliability, as a failure in one service does not affect the rest of the system.
Choreography is often used in event-driven systems and is an alternative to the centralized coordination provided by a central authority, such as a service registry or a centralized API gateway.
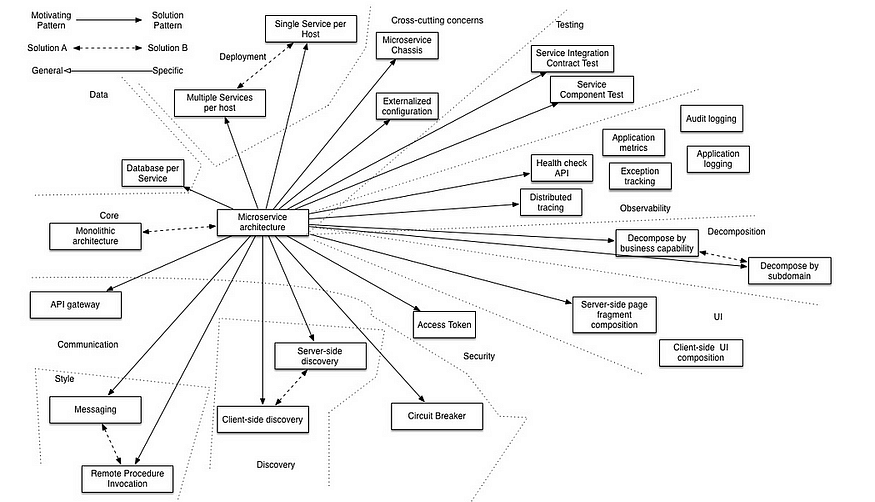
Question 96: Explain the circuit breaker concept and how to implement it?
A circuit breaker is a design pattern used to protect a system from failures of independent services. The idea behind a circuit breaker is to detect when a service is failing and to prevent further requests from being sent to that service. This helps to prevent cascading failures and to improve the resilience of the overall system.
A circuit breaker can be implemented by adding a layer between the calling service and the dependent service. This layer acts as a switch, allowing requests to pass through when the dependent service is healthy, and blocking requests when the dependent service is unhealthy. The circuit breaker also monitors the health of the dependent service and provides a mechanism for triggering a failover to a backup service if necessary.
Here are the steps to implement a circuit breaker in a microservices architecture:
Monitor the health of the dependent service by tracking the success or failure of requests.
Implement a threshold for the number of failures allowed before the circuit breaker trips and prevents further requests.
Implement a timeout for requests to the dependent service to prevent slow responses from affecting the performance of the calling service.
Implement a mechanism for tripping the circuit breaker, such as a timer or a counter that tracks the number of failures.
Implement a mechanism for resetting the circuit breaker, such as a timer or a manual reset.
Provide a fallback mechanism, such as a backup service or a default response, to handle requests when the circuit breaker is tripped.
By implementing a circuit breaker, you can improve the resilience and fault tolerance of your system, allowing it to handle failures in dependent services and recover more quickly from those failures.
There are several libraries and frameworks available for implementing circuit breakers in various programming languages. Some of the popular ones include:
Hystrix (Java): A library developed by Netflix, it is one of the most popular circuit breaker implementations for Java.
Resilience4j (Java): An lightweight, easy-to-use library for fault tolerance in Java.
Polly (.NET): A library for .NET that provides support for circuit breakers, timeouts, and retries.
Ruby Circuit Breaker (Ruby): A library for Ruby that implements the circuit breaker pattern.
Go-Hystrix (Go): A Go implementation of the Hystrix library, providing circuit breaker functionality for Go applications.
Elixir Circuit Breaker (Elixir): An implementation of the circuit breaker pattern for Elixir applications.
These libraries provide a convenient and easy-to-use way to implement circuit breakers in your applications, allowing you to improve the resilience and fault tolerance of your system.
Explain the Spring-Boot annotations for Circuit-Breaker’s
In Spring Boot, circuit breakers can be implemented using the spring-cloud-starter-circuit-breaker library, which provides support for several different circuit breaker implementations, including Hystrix.
To use the circuit breaker in Spring Boot, you can use the following annotations:
@HystrixCommand: This annotation is used to wrap a method with a circuit breaker. When the circuit breaker trips, the method will return a fallback response instead of the normal response.
@HystrixProperty: This annotation is used to configure the properties of the circuit breaker, such as the timeout and the number of failures before the circuit breaker trips.
Here is an example of how to use the @HystrixCommand and @HystrixProperty annotations to implement a circuit breaker in Spring Boot:
@Service
public class MyService {
@HystrixCommand(fallbackMethod = "fallback", commandProperties = {
@HystrixProperty(name="execution.isolation.thread.timeoutInMilliseconds",
value = "2000"),
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold",
value = "5"),
@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage",
value = "50"),
@HystrixProperty(name = "circuitBreaker.sleepWindowInMilliseconds",
value = "5000")
})
public String callDependency() {
// Call the dependent service
}
public String fallback() {
// Return a fallback response
}
}
Question 97: Design an application where you are getting millions of requests how will you design the application?
Designing an application to handle millions of requests requires careful consideration of various factors such as scalability, performance, reliability, and security. Here are some steps to design such an application:
Use a load balancer: A load balancer distributes incoming requests across multiple servers to ensure that no single server gets overwhelmed. This distributes the load and provides redundancy and fault tolerance.
Choose the right architecture: Microservice, serverless, or monolithic architecture can all work depending on the specific use case. Microservices allow for more flexibility and can handle scale better but are more complex to manage. Serverless architecture can automatically scale to handle the load but may have limitations on customization.
Use a distributed cache: A distributed cache can help reduce the load on the database by storing frequently accessed data in memory. This can speed up the application’s response time and reduce the number of database queries.
Optimize database performance: Databases are often a bottleneck in highly scalable applications. To optimize database performance, use techniques like indexing, caching and partitioning.
Implement asynchronous processing: By using asynchronous processing, the application can handle multiple requests at the same time, improving performance and scalability.
Implement caching: Implementing caching can help reduce the load on servers by serving frequently accessed content from a cache instead of generating it dynamically each time.
Use Content Delivery Network (CDN): CDN is a network of servers that can distribute content globally, delivering it from the closest server to the user, thus reducing the latency and improving the application’s performance.
Use containers and orchestration tools: Containers like Docker can help to package applications and their dependencies, allowing them to be deployed and scaled quickly. Orchestration tools like Kubernetes or Docker Swarm can automate the deployment and management of containers.
Use a distributed file system: A distributed file system can help with scalability and redundancy by distributing files across multiple servers.
Monitor and optimize: Monitor the application’s performance and usage patterns and optimize the infrastructure accordingly. Implementing logging, monitoring, and alerting can help detect issues and optimize performance in real time.
Overall, designing an application to handle millions of requests requires a combination of techniques and tools to ensure scalability, performance, reliability, and security.
Question 98: Suppose you have an application where the user wants the order history to be generated, and that history pdf generation take almost 15 minute how will you optimise this solution. How this can be reduced.
Generating a PDF of order history that takes 15 minutes can be a frustrating experience for the user. Here are some ways to optimize this process and reduce the time it takes to generate the PDF:
Optimize the database queries: The slow generation of a PDF could be due to slow database queries. You can optimize the database queries by using indexing, caching, and partitioning. This will help the queries execute faster, and the PDF generation time will be reduced.
Generate the PDF asynchronously: You can generate the PDF in the background while the user continues to use the application. This way, the user will not have to wait for the PDF to be generated. You can also notify the user when the PDF is ready to be downloaded.
Use a queueing system: Instead of generating the PDF immediately, you can put the request in a queue and generate it later. This way, the user will not have to wait, and the server can generate the PDF when it is free. You can use a queueing system like RabbitMQ or Apache Kafka for this purpose.
Use a caching system: You can cache the generated PDF and serve it to subsequent requests. This way, if the same user requests the same PDF, you can serve it from the cache, and the user will not have to wait for the PDF to be generated.
Optimize the PDF generation code: You can optimize the PDF generation code to make it more efficient. This may involve changing the libraries or tools you are using or optimizing the code itself.
Use a distributed system: You can distribute the PDF generation task across multiple servers to reduce the time it takes to generate the PDF. This is especially useful if you have a large number of users requesting the PDF.
Optimize the server: You can optimize the server to handle the load better. This may involve increasing the server’s processing power, memory, or storage.
In summary, to reduce the time it takes to generate a PDF of order history, you can optimize the database queries, generate the PDF asynchronously, use a queueing system, use a caching system, optimize the PDF generation code, use a distributed system, and optimize the server. By implementing one or more of these solutions, you can significantly reduce the time it takes to generate the PDF and improve the user experience.
Question 99: Difference between Aggregation vs composition?
Aggregation and composition are two fundamental concepts in object-oriented programming (OOP) that describe the relationships between classes and objects.
Aggregation refers to the relationship between two objects where one object “has-a” another object, but the second object can exist independently of the first object. In other words, the first object owns or contains the second object, but the second object can also exist on its own.
Composition, on the other hand, is a stronger form of aggregation where the second object cannot exist without the first object. In other words, the first object “owns” the second object, and the second object cannot exist outside the context of the first object.
In terms of implementation, aggregation is typically implemented using a reference or pointer to the second object within the first object, while the composition is typically implemented using a member variable or instance variable within the first object that is an instance of the second object.
To summarize, the main difference between aggregation and composition is the strength of the relationship between the two objects. Aggregation is a weaker form of relationship where the second object can exist independently of the first object, while the composition is a stronger form of relationship where the second object is a vital part of the first object and cannot exist without it.
Question 100: How to restrict object creation in java?
In Java, you can restrict object creation in several ways. Here are a few common techniques:
Declare the constructor as private: By declaring the constructor as private, you prevent the creation of objects of that class from outside the class. However, objects can still be created within the class itself or by its nested classes. For example:
public class MyClass {
private MyClass() {
// private constructor
}
public static MyClass create() {
return new MyClass();
}
}
In this example, the constructor is declared private, but a static factory method create() is provided to create instances of the class.
Declare the class as abstract: An abstract class cannot be instantiated directly. However, it can be subclassed, and the subclass can be instantiated. This technique is useful when you want to provide a base class but want to prevent direct instantiation of the base class itself.
public abstract class MyClass {
// abstract class
}
Use the enum type: An enum type is a special type of class that has a fixed set of values. Enum values are constants, and you cannot create new instances of them. For example:
public enum MyEnum {
VALUE1,
VALUE2,
VALUE3
}
These are a few techniques that can be used to restrict object creation in Java.